논문 읽기전 사전설명
평생학습이란?
- 인간의 뇌는 배경지식을 바탕으로 새로운 것을 배우며, 과거의 지식을 잊지 않음.
- Lifelong learning은 인간의 인지를 모방하여 치명적 망각(Catastrophic forgetting) 문제와 의미변화(Semantic drift)를 해결하기 위해 등장
- 그중 memory 접근법은 생물학적 기억 매커니즘을 모방하자는 아이디어에서 출발했으며, 대표적으로 DGR이있음
- 즉, 과거의 episodic memory system에 의존하지만. 하지만 모두 기억하기에는 너무 큰 메모리가 소요된다는 단점이있으며, 이에 대한 대안으로 나온 것이 DGR
DGR (Deep Generative Replay)이란?
- 뇌의 해마를 모방하여 만든 알고리즘. 해마는 감각정보를 단기간 저장하고 있다가, 대뇌피질로 보내 장기기억으로 저장 or 삭제를 함. 이런 단기기억&장기기억의 상보적 학습 관계를 generator와 solver로 구현
- 과거의 데이터를 저장하지 않으며, 대신 generate된 pseudo-data를 동시에 replay한다.
- 즉, 과거의 데이터를 따라하는 유사 데이터(pseudo-data)를 만들기 위해 generator가 사용됨.
- Generator는 GAN을 기반으로함. GAN으로 학습했던 데이터와 유사한 데이터를 재현(replay)함으로써 해마다 단기기억을 저장하는 것과 같은 역할을함
- Solver는 주어진 task를 해결하는 장기기억의 역할. 새로운 task를 학습할 때 Generator가 생성한 이전 task에 대한 데이터를 동시에 학습. Task A와 Task B의 데이터를 모두 학습하는 것과 같은 효과 발생하여 모델이 Multi task를 수행하도록 함.
여기서 부터는 Continual Learning with Deep Generative Replay 논문 리뷰
2.2 Deep Generative Models
- GEN 프레임워크는 generator G 와 discriminator D 사이에 일종의 제로섬 게임을 한다. D가 두 데이터 분포를 비교하여 생성된 샘플과 실제 샘플을 구별하는 방법을 배우는 동안 G는 가능한 한 실제 분포를 모방하는 방법을 학습
3. Generative Replay
- 먼저 용어를 정의할 것, 우리의 연속적인 학습 프레임워크에서 우리는 N개의 tasks들의 task 순서 T = (T1,T2 …,Tn)로 풀어야할 task 순서를 정의함
- Definition 1. Task Ti는 학습 예시 (xi,yi)를 추출한 데이터 분포 Di의 objective를 향해 모델을 최적화 하는 것이다.
- 다음으로 우리의 model은 새로운 task를 배우고 그 지식을 다른 네트워크에 학습시킬 수 있기 때문에 우리의 model을 scholar라고 부를 것.
- Definition 2. scholar H는 튜플 (G Si)로 이루어져 있음. G는 실제와 같은 샘플을 생성하는 generative model이고, S는 세타에 의해 매개변수화된 task solving model이다.
- Solver는 task sequence T의 모든 task를 수행해야한다. 전체 목표는 task sequence의 모든 task간 편향되지 않는 loss들의 합계를 최소화하는 것. 여기서 D는 전체 데이터 분포이고 L는 손실함수이다. Ti task를 위해 학습하는 동안에도 모델은 Di에서 추출한 샘플을 제공받음.
- 쉽게 말하면, generator는 replayed 된 input data를 생성하고, solver는 real data + generated input 두종류의 데이터를 사용하여 모델을 학습, 이런 generator와 solver를 합친 것을 scholar 모델이라 부름
3.1 Proposed Method
- scholar model에 대한 순차적 교육을 고려할 것. single scholar model을 가장 최근의 copy of the network을 참조하여 학습하는 것은 N번째 scholar가 현재 task와 이전 scholar의 konwledge를 학습하는 과정을 의미하는 sequence of scholar models 학습하는 것과 같음
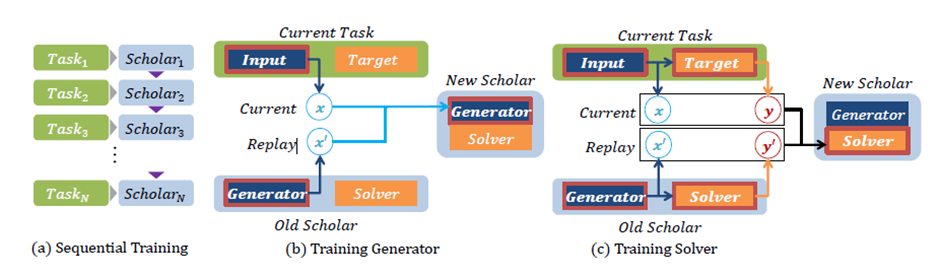
- 다른 scholar로부터 온 scholar 모델을 학습하는 것은 generator 와 solver를 학습시키는 두가지의 독립적인 절차를 거친다.
- 첫째, 새로운 generator는 현재 task의 input x와 이전 task로부터 replay 된 input x를 전송받음.
- Real sample과 replayed sample은 이전 task에 비해 새 task에서 요구하는 중요도에 따른 비율로 혼합됨
- Generator는 cumulative input space을 재구성하는 방법을 학습하고, 새 solver는 실제& repaly 된데이터와 동일한 혼합에서 나온 타겟을 input에 결합하도록 학습됨.
- 여기서 replay된 target은 replay된 input에 대한 solver의 응답을 지나친다. 아래는 i번째 solver에 대한 loss function이다.
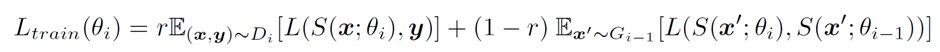
- 세타i는 i번째 scholar의 네트워크 파라미터이고, r은 mixing 된 real data의 비율이다. 우는 original task에서 model을 평가하는 것을 목표로 하기 때문에, test loss는 조금 다르며 아래와 같다.

- 여기서 Dpast는 과거 데이터의 누적 분포, i=1일때는 첫번째 solver에 대해 참조할 재생데이터가 없고 LEOAN 두기능 모두 두번째 loss항이 무시됨.
- 우리는 scholar model을 task sequence를 해결하는데에 적합한 아키텍처를 가진 solver와 GAN 프레임워크에서 학습된 generator를 사용하여 scolor 모델 구축했으며, 우리의 framework는 모든 deep generative model도 generator로 사용할 수 있
3.2 Preliminary Experiment
- 학습된 scholar 모델만으로도 비어 있는 network를 훈련시키기에 충분하다는 걸 보여주기 위한 실험. MNIST 숫자 DB 분류에 대한 모델을 테스트 했음.
- Scholar 모델 sequence는 이전 scholar로부터 generative replay을 통해 처음부터 훈련되었음, 전체 데이터셋을 분류하는 정확도는 표1에 나와있다.

- 첫 번째 solver는 실제 데이터로부터 배우고, 후속 solver는 이전 scholar 네트워크에서 GR을 통해 처음부터 훈련되었음.
- scholar 모델이 정보를 잃지 않고 지식을 전달하는 것을 관찰
4. Experiments
- 본 섹션에서는 다양한 평생학습 설정에 대한 generative replay framework의 적용가능성을 보여줌.
- 훈련된 scholar network를 기반으로한 Generative replay은 생성 모델의 품질이 작업 성능의 유일한 제약 조건이라는 점에서 다른 연속 학습 접근 방식보다 우수. 즉, 생성 모델이 최상일 때 Generative replay를 통해 네트워크를 학습시키는 것은 전체 데이터셋을 동시에 학습시키는 것과 같음.
- 기본실험으로, 섹션 4.1에서는 망각의 정도를 조사하기위해 독립 task에 대한 네트워크를 순차적으로 훈련함. 섹션 4.2에서는 서로 다른 두개의 관련된 도메인에서 네트워크를 학습시킴. 이는 generative replay가 알려진 다른 구조와도 호환 가능하다는 것을 보여줌. 섹션 4.3에서는 학습데이터의 분리된 하위 집합에 대한 네트워크를 학습시킴으로써, 우리의 scholar 네트워크가 meta task를 수행하기 위해 다양한 task로부터 지식을 수집할 수 있음을 보여줌.
보다 자세한 내용을 보고싶다면 아래의 링크의 원문을 참고하세요!
Continual Learning with Deep Generative Replay
Attempts to train a comprehensive artificial intelligence capable of solving multiple tasks have been impeded by a chronic problem called catastrophic forgetting. Although simply replaying all previous data alleviates the problem, it requires large memory
arxiv.org
'AI' 카테고리의 다른 글
| [Python/ ML] 넘파이(numpy)를 이용한 간단한 행렬 연산 (shape, ndim, reshape) (0) | 2022.01.06 |
|---|